
Datenbankdateien, Filegruppen und Transaktionen
Jede Datenbank besteht aus einer primären und mehreren sekundären Dateien. Die primäre Datei hat die Endung .mdf. Die sekundären Dateien haben die Endung .ndf.
Die Speicherorte der Dateien (Pfade) werden in der master- DB und in der primären Datei der DB selbst verzeichnet
Namensgebung
"font-weight: normal"> Datenbankdateien haben einen logischen und einen physischen Namen. Der logische Name wird in TSQL verwendet.
|
Logischer Name (z.B. FileSysDB) |
Physischer Name (z.B: c:\db\filesysdb.mdf) |
Aufbau
Der Speicherplatz für eine Datenbankdatei wird blockweise reserviert. Jeder Block besteht aus 8 Seiten, die jeweils 8 KB Daten aufnehmen.
Jede Seite nimmt die Daten genau eines Datenbank- oder Dateiorganisationsobjektes auf. Blöcke, in denen alle Seiten mit Daten eines einzigen Datenbankobjekt belegt sind, werden als einheitliche Blöcke bezeichnet. Werden in den Seiten eines Blockes Daten zu verschiedenen Datenbankobjekten abgespeichert, dann ist der Block ein gemischter Block.
Das Verzeichnis aller Seiten, die ein Datenbankobjekt belegt ist ie IAM (Index Allocation Map)
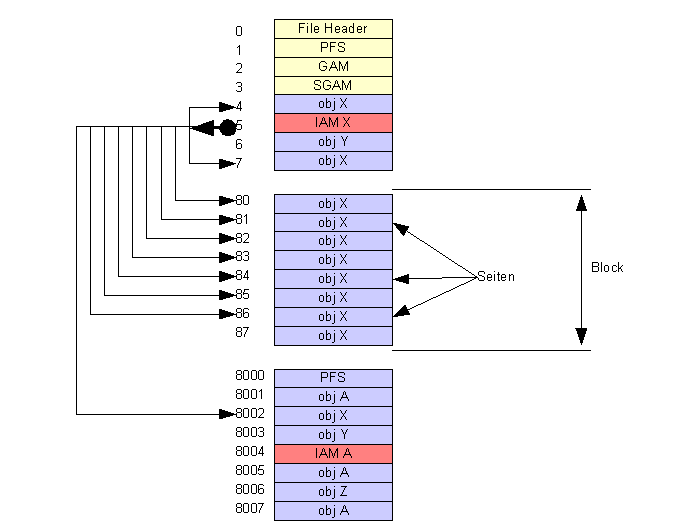
Der erste Block einer Datei enthält den Kopf mit organisatorischen Infos:
|
Seite |
Name |
Inhalt |
Beschreibung |
|---|---|---|---|
|
0 |
FileHeader |
DateiID |
|
|
Anfangsgrösse der Datei |
|
||
|
max. Dateigrösse |
|
||
|
1 |
PFS |
Page Free Space |
Die PFS verzeichnet für jede Seite den Belegungszustand. Abstufungen: leer, 1-50%, 51-80%, 81-95%, >95% |
|
2 |
GAM |
Global Allocation Map |
Jedes Bit in der GAM kennzeichnet die Belegung eines Blocks in der Datei. Ist das Bit 0, dann ist der Block noch frei, sonst ist er belegt. Insgesamt können 64000 Blöcke (= 4 GB)verzeichnet werdn. |
|
3 |
SGAM |
Secondary Global Allocation Map |
Jedes auf 1 gesetzte Bit in der SGAM kennzeichnet einen gemischten Block, in dem noch midestens eine Seite frei ist. |
Heap
Daten eines Datenbankobjektes, die nicht indiziert sind, werden in Seiten gespeichert, die dem Datenbankobjekt über die IAM zugeordnet sind, und in denen noch Speicherplatz vorhanden ist. Sollte der Speicherplatz nicht mehr ausreichen, dann werden der IAM neue Seiten zugeteilt. Dies kann die Reservierung neuer Blöcke nach sich ziehen usw.. Diese ungeordnete Ablage der Daten nach dem Prinzip "Speichern wo Platz ist" wird Heap genannt.
Der Zugriff auf Daten, die nach dem Heap- Prinzip abgelegt wurden, ist aufwendig und kann im schlimsten Fall das Durchsuchen der gesamten Datensammlung zur Folge haben.
Indizes
Werden die Datensätze beim Einfügen in die Datensammlung bezüglich eines Ordnungskriteriums geordnet, dann kann der Zugriff durch Nutzung der Ordnung stark beschleunigt werden. Das Ordnen beim Einfügen wird Indizierung genannt.
Gruppierte Indizes (Clustered Index)
Gruppierte Indizes sorgen für eine physiche Ordnung der Datensätze, dh. wenn die Daten nach dem < Kriterium geordnet werden, dann sind die Kleineren Werte auf Seiten mit kleinerer Seitennummer, und größere Werte auf Seiten mit größerer Seitennummer zu finden.
Gruppierte Indizes können zur Folge haben, daß beim Hinzufügen von Daten der Speicherort vorher eingefügter Datensätze verschoben werden muß. Dies vermindert die Leistung bei Einfügeoperationen.
Nicht gruppierte Indizes (Nonclustured Index)
Nicht gruppierte Indizes bewirken keine physiche Ordnung der Datensätze. Der Index ist ein B- Baum, dessen Blätter auf die Speicherorte der Datensätze zeigen. Werden die Blätter des B- Baum von links nach rechts durchlaufen, dann können alle Datensätze in aufsteigender Folge gemäß dem Ordnungskriterium besucht werden.
Transaktionssystem: Protokolldateien
Alle Datenbankänderungen können in Transaktionsprotokolldateien mitprotokolliert werden. Dadurch sind bei einem Systemausfall verloren gegangene Daten wiederherstellbar, bzw. die Datenbank kann wieder in einen konsitstenten Zustand überführt werden. Gespeichert werden die Transaktionsprotokolle in Dateien mit der Endung .ldf.
Funktionsweise der Protokollierung
![]()
Prüfpunkt (Checkpoint-) Prozess
Der Prüfpunkt- Prozess sorgt periodisch für die Sicherung der geänderten Datenseiten im Puffercache auf der mdf- Datei auf Platte. Nach einem Prüfpunkt sind alle Datenänderungen auch auf der Festplatte verzeichnet. Sollte das System unmittelbar nach einem Prüfpunkt ausfallen, dann sind beim Hochfahren des Servers nur die Anweisungen aller bestätigten Transaktionen aus dem Protokoll wiederholt auszuführen, die nach dem Prüfpunkt eröffnet wurden.
Einstellen des Prüfpunktintervalles
use kraftstoff go -- Voraussetzungen schaffen, um Prüfpunkte einzustellen (siehe SQL- Server- Hilfe) exec sp_configure 'show advanced options', 1 reconfigure go -- Prüfpunktintervall einstellen exec sp_configure 'recovery interval', 2 reconfigure go
Wird 0 Min eingestellt, dann entscheidet der Server selbst, wann Prüfpunkte gesetzt werden müssen.
Manueller Prüfpunkt
Ein Prüfpunkt kann manuell mit der Anweisung CHECKPOINT gesetzt werden. Jedoch muss das Script unter einem Konto mit der Rolle db_owner laufen.
Verwaltung der Transaktionsprotokolle
Ein Transaktionsprotokoll ist unterteilt in sog. virtuelle Protokolle.
Jede Folge von Änderungen an der Datenbank wird durch eine Folge spezieller Datensätze (Logs) in der Protokolldatei aufgezeichnet. Jeder Datensatz erhält dabei eine LSN (Log Sequenz Number). Der Beginn der ältesten, noch nicht abgeschlossenen Transaktion wird durch die MinLSN angezeigt. Die letzte Änderung, die bereits aus dem Puffercache in die Datenbank zurückgeschrieben wurde wird durch den letzten Prüfpunkt angezeigt.
![]() Durch
sichern der Transaktonsprotokolle werden die virtuellen Protokolle
wieder freigegeben, die keine Daten zu aktuell aktiven Transaktionen
beinhalten. Dieser Vorgang wird als Abschneiden bezeichnet. Die
freigegebenen virtuellen Protokolle können dann wieder für
die Aufzeichnung der Logs verwendet werden.
Durch
sichern der Transaktonsprotokolle werden die virtuellen Protokolle
wieder freigegeben, die keine Daten zu aktuell aktiven Transaktionen
beinhalten. Dieser Vorgang wird als Abschneiden bezeichnet. Die
freigegebenen virtuellen Protokolle können dann wieder für
die Aufzeichnung der Logs verwendet werden.
Wiederherstellungsmodelle für Transaktionsprotokolldateien
Die Protokollierung aller Änderungen an einer Datenbank kann sehr Speicherplatz verbrauchen. Deshalb gibt es die Möglichkeit, den Umfang der Protokollierung einzuschränken. Dies geschieht über sog. Wiederherstellungsmodelle. Natürlich geht bei eingeschränkter Protokollierung Redundanz verloren, wodurch das Risiko für irreversible Datenverluste steigt.
|
Vollständige |
Massenprotokolliert |
Einfach |
|---|---|---|
|
|
|
Der Wiederherstellungsmodus kann durch folgende TSQL- Anweisung bestimmt werden:
select DATABASEPROPERTYEX('<datenbankname>', 'recovery')
go
Aufteilen der Daten auf Datenbankdateien
Die Informationen einer Datenbank verteilen sich auf mehrere Dateien. Die Datenbankinhalte sind in Dateien mit der Extension *.mdf und *.ndf enthalten. Die Transaktionsprotokolle werden in separaten Dateien mit der Extension *.ldf gespeichert.
Die Dateien einer Datenbank werden in primäre und sekundäre Dateien klassifiziert. Jede Datenbank hat eine primäre Datei mit den Startinfos der Datenbank + Datenbankobjekten wie Tabellen etc.. Reicht z.B. der Platz auf einer Fetplattenpartition nicht mehr für die Speicherung aller Datenbankobjekte aus, dann können mittels sekundärer Partitionen auf anderen Festplatten zusätzlich Speicherplatz bereitgestellt werden. Im Enterprisemanager kann in der Eigenschaftliste einer Datenbank die Zuordnung weiterer sekundärer Datandateien vorgenommen werden.
"font-style: normal"> Mittels Dateigruppen können mehrere sekundäre Dateien zusammengefasst werden. Beim Erstellen einer Tabelle kann ihr als Speicherplatz eine Dateigruppe zugewiesen werden. Verteilen sich die Dateien einer Dateigruppe auf mehrere Festplatten, kann so ein Leistungssteigerung ähnlich wie bei einem RAID5 System erreicht werden.
Wichtig: Daten- und Transaktionsprotokolldateien von Microsoft® SQL Server™ 2000 dürfen nicht auf komprimierten Dateisystemen oder auf einem Remotenetzlaufwerk, z. B. einem freigegebenen Netzwerkverzeichnis, erstellt werden.
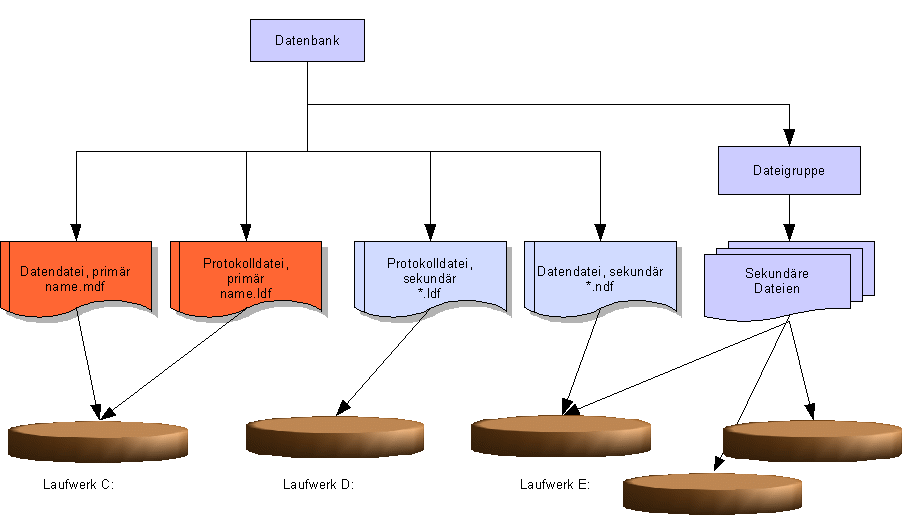
Anlegen mittels TSQL
Datenbanken werden mittels create database angelegt. Beispiel:
use master go if exists(select * from master.dbo.sysdatabases where name ='mko_report') drop database mko_report go create database mko_report ON -- Definition der Datendatei PRIMARY ( NAME = report_dat, FILENAME = 'c:\sql_mko_report.mdf', SIZE = 5 MB, MAXSIZE = 10 MB, FILEGROWTH = 100 KB ) ( NAME = report_dat, FILENAME = 'e:\sql_mko_report2.mdf', SIZE = 5 MB, MAXSIZE = 10 MB, FILEGROWTH = 100 KB ) -- Definition der Log- Datei LOG ON ( NAME = Sales_log, FILENAME = 'c:\sql_mko_report_log.ldf', SIZE = 5 MB, MAXSIZE = 10 MB, FILEGROWTH = 100 KB ) GO
Existierende Datenbankdateien an den Server anbinden und abkoppeln
Um existierende Datenbankdateien an den Server anzubinden, ist folgende Variante von create Database anzuwenden.
use master go create database geoinfo on (filename = 'c:\mydb\geoinfo.mdf') log on (filename = 'c:\mydb\geoinfo.ldf') for attach
Alternativ kann die Datenbank im Enterprisemanager über Datenbanken\Kontextmenü\Alle Tasks\Datenbank anhängen wieder angehangen werden.
Datenbanken können vom Server wieder abgekoppelt werden, um sie z.B. an einen Anwender zu senden. Dies geschieht mittels einer Prozedur:
use master go exec sp_detach 'geoinfo' go
Alternativ kann die Datenbank im Enterprisemanager über Datenbanken\<Datenbankname>\Kontextmenü\Alle Tasks\Trennen abgekoppelt werden.
Datenbankoptionen
Die Datenbankoptionen können eingestellt werden über
-
Enterprisemanager/<Serverinstanz>/Datenbanken/<Kontextmenü der Datenbank>/Eigenschaften/Optionen
-
oder mittels der gespeicherten Prozedur ALTER DATABASE SET ...
Wichtige Optionen für Wartungsaufgaben
|
Option |
Beschreibung |
|---|---|
|
SINGLE_USER |
Einzelbenutzermodus Zu jedem Zeitpunkt kann nur ein Benutzer auf die Datenbank zugereifen |
|
REStrICTED_USER |
Zugriff nur für Mitglieder von db_owner, db_creator oder sysadmin |
|
MULTI_USER |
|
|
READ_ONLY | READ_WRITE
|
Datenbank ist entwerder Schreibgeschützt (READ_ONLY) und kann nicht verwendet werden, oder User können auf die Datenbank lesend und schreibend zugreifen (READ_WRITE) |
Informationen zu Datenbanken abfragen
Eine Übersicht zu allen eingerichteten Datenbanken auf einer Serverinstanz kann mit folgender Prozedur gewonnen werden.
exec sp_helpdb go
Speicherplatzbelegung der Datenbanken explizit abfragen
exec sp_spaceused go
Speicherplatzbedarf einer Tabelle in einer Datenbank abfragen
use Hypercube go exec sp_spaceused 'dbo.FactFiles' go