
MS- TSQL
Transact- SQL
Transact- SQL (kurz T- SQL) ist eine Microsoft- Erweiterung von SQL. Sie umfasst die DML und DDL des SQL92 Standards (Entry- Level), und erweiterungen wie Variablen und Kontrollanweisungen (z.B. IF... und While).
Sprachelemente
|
DCL |
DDL |
DML |
Variabeln |
Kontrollanweisungen |
|---|---|---|---|---|
|
engl: Data Control Language GRANT ... DENY ... REVOKE ... |
engl.: Data Definition Language CREATE type object_name ALTER type object_name DROP type object_name |
engl.: Date Manipulation Language SELECT ... INSERT ... UPDATE ... DELETE ... |
Eine Variabel ist ein benannter Hauptspeicherplatz und dient zur temporären Speicherung von Zwischenergebnissen. declare @anz_laender int set @anz_laender = 1 |
Kontrollanweisungen beeinflussen den Programmablauf if @x > 1 select ... else print ... |
Kommentare
-- Einzeiliger Kommentar /* Blockkommentar hier endet der Kommentar */
Bezeichner
|
Definition |
|
|---|---|
|
Bezeichner |
Ein Bezeichner ist eine ein Name für eine Variabel, eine Prozedur oder ein Datenbankobjekt. |
Es gibt zwei Arten von Bezeichnern:
- reguläre Bezeichner
- begrenzte Bezeichner
Begrenzte Bezeichner können Leerzeichen enthalten. Enthält ein Bezeichner Schlüsselwörter von T-SQL, dann muss er als begrenzter Bezeichner verpackt werden.
Damit ein begrenzter Bezeichner vom Compiler als eine Einheit erkannt werden kann, muß er in eckigen Klammern bzw. doppelten Anführungszeichen eingefasst werden.
Select * FROM [Tab Länderinformationen];
Anweisungen
Anweisungen (engl. Statements) sind Operationen, die den Zustand des Systems verändern.
S → S' und S == S' gilt nicht allgemein S: Zustand vor Ausführung der Anweisung → Anweisung S': Zustand nach Ausführung der AnweisungSeit SQL Server 2008 sollten Anweisungen, wie im ANSI Standard vorgesehen, mit stets mit einem Semikolon (
;) abgeschlossen werden.
Gr�nde dazu kann man hier.
NOP
Die einzige Anweisung, die den Zustand des Systems unverÄndert lÄsst (NOP=No Operation), ist die leere Anweisung:
-- nichts passiert ; -- nach vielen leeren Anweisungen ist immer noch nichts passiert ;;;;;;
use
Mittels use Datenbankname wird die aktuelle Sitzung mit einer Datenbank verbunden.
use geoinfo;
go
Schließt einen Batch syntaktisch ab. Der Interpreter führt alle Anweisungen zwischen vorausgegangenen go und aktuellen go aus. go Wird von Dienstprogrammen wie osql und Query Analyser ausgewertet, ist jedoch kein echter Bestandteil von SQL.
use geoinfo go
exec
Mit exec werden gespeicherte Prozeduren und Selbstdefinierte Funktionen aufgerufen:
exec sp_who;
print 'hallo Welt' go
Declare
Mittels Declare werden neue Variablen deklariert
Set
Set definiert die Zuweisung eines Wertes an eine Variable
Variablen
Variablen können in Batchs und Stored Porzedures genutzt, um Werte zwischenzuspeichern.
-- Deklaration einer Variablen DECLARE @name varchar(50); -- Setzen einer SET name = 'Willi';
Operatoren
Operatoren sind grundlegende Verknüpfungen auf einer bestimmten Menge.
Like- Operator
Der Like- Operator prüft, ob ein Muster auf eine Zeichenkette passt. Wenn sie passt, dann wird trUE zurückgegeben, sonst FALSE. Die Muster können dabei Platzhalter der folgenden Art enthalten:
|
Platzhalter |
Beschreibung |
Beispiel |
|---|---|---|
|
% |
Eine Zeichenfolge aus null oder mehr Zeichen |
WHERE title LIKE '%Computer%' findet alle Buchtitel, die das Wort 'Computer' enthalten. |
|
_ (Unterstrich) |
Ein einzelnes Zeichen |
WHERE au_fname LIKE '_ean' findet alle Vornamen mit vier Buchstaben, die auf ean enden (Dean, Sean usw.). |
|
[ ] |
Beliebiges einzelnes Zeichen im angegebenen Bereich ([a-f]) oder in der angegebenen Menge ([abcdef]). |
WHERE au_lname LIKE '[C-P]arsen' findet alle Autorennachnamen, die auf arsen enden und mit einem einzelnen Zeichen zwischen C und P beginnen, z. B.: Carsen, Larsen, Karsen usw. |
|
[^] |
Beliebiges einzelnes Zeichen, das sich nicht im angegebenen Bereich ([^a-f]) oder in der angegebenen Menge ([^abcdef]) befindet. |
WHERE au_lname LIKE 'de[^l]%' findet alle Autorennachnamen, die mit de beginnen und deren dritter Buchstabe nicht l ist. |
Operatoren der ganzen Zahlen
DECLARE @a int, @b int, @c int set @a = 7 set @b = 3 set @c = @a * @b -- Multiplikation set @c = @a / @b -- Division set @c = @a % @b -- Modulo set @c = @a + @b -- Addition set @c = @a - @b -- Subtraktion
Datentypen
SQL Server besitzt fest vordefinierte Basisdatentypen. Über die Definition von Einschränkungen können aus den Basisdatentypen benutzerdefinierte Typen gewonnen werden.
|
Typ |
Beschreibung |
Beispiel |
|---|---|---|
|
binary
|
Bitfolgen. Werden alse Folge von Hexzahlen dargestellt. Bei binary ist die Anzahl der Speicherplätze in Bytes fest anzugeben. varbinary passt die Länge dem Bedarf automatisch an. In beiden Fällen darf die Länge nicht mehr als 8 KB betragen. Image ist wie varbinary. Hier darf die Länge jedoch 8 KB überschreiten. Ab SQL Server 2005 sollte anstatt image varbinary(max) eingesetzt werden |
create table maschinecodes ( pos int, code binary(3) ) go insert into maschinecodes values (1, A1F2D3) go |
|
varbinary |
||
|
image bzw. varbinary(max) |
||
|
char |
Zeichendaten mit fester Länge (max. 8KB) |
create table buecher (
isbn char(20),
titel varchar,
inhalt text
)
go
insert into buecher (
('3-930673-56-8', 'JavaScript', 'bla bla ....')
go
-- Wie kann man ein Apostroph in einem Text darstellen,
–- wenn Apostrophe Textbegrenzer sind ?
-- Antwort: mit doppeltem Apostroph ''
Set @txt = N'Nu is''s vollbracht'
|
|
varchar |
Zeichendaten variabler Länge (max. 8KB) |
|
|
text bzw. varchar(max) |
Zeichendaten variabler Länge (> 8KB) |
|
|
datetime |
Datum und Uhrzeit. SQL- Server kennt keine separaten Typen für nur Datum und nur Uhrzeit Wertebereich: 1.1.1753 bis 31.12.9999 |
create table termine (
zeit datetime,
thema varchar
)
go
set dateformat dmy
go
insert into termine values
('3/9/2003 19:00', 'Zahnartzt')
go
|
|
smalldatetime |
Datum und Uhrzeit. Wertebereich: 1.1.1900 bis 6.6.2079 |
|
|
decimal |
Festkommazahlen mit bis zu 38 Ziffern |
create table lebensmittellager (
artikel char(4),
einwage dec(3,3), -- in kg
preis dec(7,2) -- in Euro
)
go
insert into lebensmittellager values
('4711', 1.237, 2.99)
go
|
|
numeric |
Synonym für decimal |
|
|
float |
Gleitpunktzahlen von -1.79E+308 bis 1.79E308 |
declare @MasseJupiterInKg float = 1.8986E+27 |
|
real |
Gleitpunktzahlen von -3.4E+38 bis 3.4E+38 |
|
|
bigint |
Festkommazahlen von -2^63 bis 2^63 – 1 |
|
|
int |
Festkommazahlen von -2^31 bis 2^31 -1 |
declare @A int = 3 declare @B int declare @C int -- Integerdivision schneidet Nachkommastellen ab Set @B = @A / 2 -- Modulo- Operation liefert den Rest Set @C = @A % 2 |
|
smallint |
Festkommazahlen von -2^15 bis 2^15 -1 |
|
|
tinyint |
Festkommazahlen von 0 bis 255 |
|
|
money |
Währungswerte (8 Byte pro Wert). Nach dem Komma werden 5 Stellen gespeichert. Damit liegt die Genauigkeit bei einem zehntausendstel einer Währungseinheit. |
create table lebensmittellager (
artikel char(4),
einwage dec(3,3), -- in kg
preis money -- in Euro
)
go
insert into lebensmittellager values
('4711', 1.237, €2.99)
go
|
|
smallmoney |
Währungswerte (4 Byte pro Wert) |
|
|
bit |
Daten mit Entscheidungsgehalt von einem Bit. Dient zur Darstellung boolscher Werte (trUE/FALSE oder YES/NO) als 0/1. |
declare @ich_sehe_fern bit if @ich_sehe_fern = 0 or @ich_sehe_fern = 1 print 'Deutsche Realitaet der Jahre 2014, 2015, ...' else print 'Marktwirtschaft'
|
|
cursor |
Kann nur für Stored Procedures mit OUTPUT- Parameter verwendet werden, die Verweis auf einen Cursor enthalten. |
|
|
timestamp |
Ist ein Zähler, der nach jeder Manipulation am Datensatz um 1 erhöht wird. Stellt damit eine Art Versionsnummer für den aktuellen Datensatz dar. |
|
|
uniqueidentifier |
16 Byte große Dezimalzahl, die einen GUID darstellt. |
create table [dms-files] (
file_id uniqueidentifier,
...
)
insert into [dms-files] (file_id) values (NewId())
|
|
SQL_variant |
Speichert werte beliebiger Datentypen, außer text, ntext, timestamp, image und sql_variant |
|
|
table |
Kann Menge von Tabellenzeilen aus einer Abfrage aufnehmen. Darf nur zur Deklaration lokaler Batch- Variabeln bzw als Rückgabewert selbstdefinierter Prozeduren eingesetzt werden. |
|
|
nchar |
Zeichenkettentypen für Unicodes analog char, varchar und text. nchar und nvarchar können maximal 4000 Unicode- Zeichen aufnehmen. |
N'€' |
|
nvarchar |
N'۩' |
|
|
ntext |
N'۩...' |
|
|
xml |
Neuer Datentyp in SQL- Server 2005. Hier können xml- Dokumente und Fragmente abgelegt, und mittels XML- Query Operationen analysiert werden. Dokumente besitzen gegenüber Fragmenten ein einziges Rootelement. Die XML- Dokumente können bis zu 2GB groß sein. |
-- Tabelle mit XML- Typ
create table data.event_log (
logtime datetime,
[log] xml
)
go
-- Variable mit XML Typ
DECLARE @logmsg xml
Set @logmsg = '<def><AddNewSchema n="doktyp.xsd"/></def>'
|
Konvertierungen zwischen den Typen
CAST(wert as Zieltype) CONVERT(Zieltyp, wert, Option)
Prüfen auf Typ
ISDATE(Ausdruck) -– Gibt 1 zurück, wenn der Ausdruck ein Datumswert ergibt, sonst 0 ISNUMERIC(Ausdruck) –- Gibt 1 zurück, wenn der Ausdruck ein nummerischer Wert ergibt, sonst 0
uniqueidentifier - GUID
uniqueidentifiers sind 128 Bit große Zahlen, die nach einem bestimmten Verfahren gebildet werden, so dass weltweit eindeutige ID's entstehen, auch GUID's (Global Unique IDentifier) genannt.
Auf GUID's sind Vergleichoperatoren definiert.
Eine neue GUID kann mittels der Funktion NewId() gewonnen werden.
Zeichenkettenfuntionen
len(Ausdruck) -- Gibt die Zeichenzahl in der durch Ausdruck gebildeten Zeichenkette
-- zurück
substring(Ausdruck, start, anz) –- Scheidet aus der durch Ausdruck gebildeten Zeichenkette ab
-- start anz Zeichen aus und gibt diese Teilzeichenkette zurück
upper(Ausdruck) -- Wandelt alle Klein- in Großbuchstaben um und gibt diese Zeichenkette
-- zurück
lower(Ausdruck) -- Wandelt alle Groß- in Kleinbuchstaben um und gibt diese Zeichenkette
-- zurück
ltrim(Ausdruck) -- entfernt alle führenden Leerzeichen
rtrim(Ausdruck) -- entfernt alle nachfolgenden LeerzeichenSoundex
Soundex ist eine Textfunktion, die einen sog. Soundex- Code zurückliefert. Ähnlich klingende Wörter liefert den gleichen Soundex- Code.
Beispiel: Der Name Meier liefert mit e oder mit a geschrieben stets den gleichen Soundex- Code M600
select soundex('Maier')Contains
MSSQL 2000 kann mit dem MSIndexServer zusammenarbeiten. Das Ergebnis sind sog. Volltextindizes, die z.B. das anspruchsvolle Contains- Prädikat ermöglichen.
Einrichten von Volltextindizes siehe S. 565 ff.
Contains gibt True zurück, wenn eine Spalte ein gesuchtes Wort enthält. Der vergleich kann dabei sehr flexibel gestaltet werden.
- Ist ein Wort in der Nähe eines zweiten enthalten ('programmieren NEAR c#')
- Ein Wort und seine Ableitungen wie programmieren -> Programmierung (' FORMSOF (INFLECTIONAL, programmieren) ')
select * from words where Contains ('programmieren NEAR c#')xml (2005)
Neuer Datentyp in SQL- Server 2005. Hier können xml- Dokumente und Fragmente abgelegt, und mittels XML- Query Operationen analysiert werden. Dokumente besitzen gegenüber Fragmenten ein einziges Rootelement. Die XML- Dokumente können bis zu 2GB groß sein.
xml Instanzen
Instanzen des Typs xml werden durch Konvertierung aus einem String erzeugt. Quelle kann dabei eine Wert eines beliebigen String- Types sein.
-- Variable mit XML Typ DECLARE @logmsg xml Set @logmsg = '<def><AddNewSchema n="doktyp.xsd"/></def>'
Einschränkungen
Operationen auf xml- Datentypen unterliegen folgenden Einschränkungen:
- sie können nicht in einer sql_variant Instanz gespeichert werden
- in ntext kann nicht konvertiert werden
- bei Spaltendefinitionen können sie nicht als primary key, foreign key, unique, collate oder rule ausgezeichnet werden
- sie können nicht sortiert, gruppiert und verglichen werden
- sie können nicht als Eingabe für eingebaute Scalarfunktionen benutzt werden (Ausnahmen: ISNULL(..), COALESCE(..), DATALENGTH(..))
- XML- Prozessorinstruktionen (<?xml ... ?>) werden vor dem Speichern entfernt.
- Die Reihenfolge der Attribute bleibt nach dem Speichern und wieder auslesen nicht erhalten
- In der Standardeinstellung werden nicht signifikante Whitespaces gelöscht
- Namespace- Prefixe werden nicht gesichert. Die Prefixe vor der Sicherung unterscheiden sich im allgemeinen von denen nach dem Lesen
Methoden des XML- Typs
Der xml- Datentyp liefert Methoden zum Analysieren und ändern des Inhaltes eines xml- Wertes. Zur Navigation und Abfrage von Werten sethen die Methoden generell XQuery ein. XQuery ist ein Stadard des w3.org und wird spezifiziert unter XQuery 1.0 Spzifikation des w3.org .
Namespaces in XQuery
Befinden sich die Elemente eines XML in Namespaces, dann müssen diese durch Deklarationen im XQuery- Ausdruck definiert werden.
Syntax:
declare namespace prefix="Namespace- Uri";
Das vereinbarte Prefix muß dann im XQuery- Ausdruck allen Knotennamen vorangestellt werden (auch wenn es sich um einen default- Namespace handelt).
select record.value(
'declare namespace n="http://www.tracs.de/xsdFotoFileinfo.xsd";
(/n:foto-fileinfo/n:bildformat/@breite)[1]', 'int') as breite
from data.recordsDie Methoden werden in einer SQL- Select Anweisung als Subqueries ausgeführt. Die mit Subqueries verknüpften Einschränkungen übertragen sich auch auf XML- Methoden.
Relationale- und Vergleichsoperatoren in XQuery
XQuery ist von der XPath- Syntax abgeleitet. Da XQuery aber nicht Bestandteil von XML Dokumenten wie XPath in XSLT ist, konnte die Sytax wesentlich komfortabler ausgelet werden. So werden die relationalen Operatoren nicht wie in XPath durch < unschrieben, sondern direkt notiert:
|
Symbol |
Operator |
|---|---|
< |
Kleiner als |
<= |
kleiner gleich |
> |
größer als |
>= |
größer gleich |
= |
gleich |
!= |
ungleich |
query(...)
Syntax:
xmlInstanz.query(XQuery)
Durch einen XQuery- Ausdruck wird eine Knotenmenge im XML- Wert definiert. Query liefert diese Knotenmenge als Fragment zurück:
-- Abfrage auf data.event_log
Select log.query('/def/AddNewSchema')
from data.event_log
-- Ergebniss sind XMLFragmente der Form '<AddNewSchema n='...'/> für alle Zeilen,
-- auf deren log- Spalte der XQuery Ausdruck passtvalue(...)
Syntax:
xmlInstanz.value(XQuery, SqlTyp)
Durch einen XQuery- Ausdruck wird ein skalarer Wert eines XML- Elementes oder Attributes im XML- Wert definiert. Value liefert diesen und konvertiert ihn dabei in den gewünschten Typ.
-- Abfrage auf data.event_log
Select log.value('(/def/AddNewSchema/@n)[1]', 'nvarchar(400)')
from data.event_log
-- Ergebniss sind nvarchar(400) Strings mit den Namen der Schemadateien,
-- die hinzugefügt wurdenexist(...)
Syntax:
xmlInstanz.exist(XQuery)
Wenn ein XML- Wert eine durch den XQuery- Ausdruck definierte Knotenmenge enthält, dann liefert die Funktion 1 zurück. Wird kein Knoten aus der definierten Knotenmenge gefunden, dann liefert die Funktion 0 zurück. Ist der XML Wert ein Null- Wert, dann wird NULL zurückgeliefert.
-- Abfrage auf data.event_log
Select *
from data.event_log
where log.exist('/def/AddNewSchema[@n="Doktyp.xsd"]')
-- Alle Zeilen, die das Fragment <def><AddNewSchema n="doktyp.xsd"/></def> enthalten
-- werden zurückgeliefertmodify(...)
Syntax:
xmlInstanz.modify(XML_DML)
Mittels der modify- Methode kann innerhalb einer SQL- Update- Anweisung in der Set- Klausel ein xml- Wert geändert werden. Dazu ist ein Spezieller XML_DML Ausdruck über die modify- Methode auf dem xml- Wert anzuwenden:
nodes(...)
Datumsfunktionen
Zeitintervalle berechnen und addieren
dateadd(Intervall, anz_intervalle, datum) –- Zum Datum wird ein Zeit- Intervall anz_intervalle mal
-- hinzuaddiert
datediff(Intervall, startdatum, enddatum) – Der Zeitraum zwischen Start und enddatum wird als Menge
-- in der Einheit Intervall zurückgegeben
-- Intervalle: year, month, week, day, hour, minute, second, millisecondTag, Monat oder Jahr aus einem Datum extrahieren
day(Ausdruck) -- gibt den Tag als Wert zw. 1 und 31 zurück month(Ausdruck) -- gibt den Monat als Wert zw. 1 und 12 zurück year(Ausdruck) -- gibt das Jahr zurück
Aktuelles Datum
declare @jetzt datetime set @jetzt = current_timestamp -- alternativ set @jetzt = getdate()
Konvertieren aus/ins ODBC- Format
Allgemein:
convert (Zieltyp, Quelltyp, Style)
Style muß bei der ODBC- Konvertierung auf 20 stehen.
Ausgabe des aktuellen Datums im yyyy-mm-dd hh:mm:ss Format
print convert(char(30), current_timestamp,20) go
Umwandeln eines ODBC DateTime- Literals in einen SQL- Server DateTime wert:
insert into UpdateLog (begin) Values (convert(DateTime, "2004-05-23 19:21:31", 20) go
Funktionen
Funktionen können in folgende Kategorien unterteilt werden:
|
Aggregatfunktionen |
Skalare Funktionen |
Rowsetfunktionen |
|---|---|---|
|
Aggregieren innerhalb einer Gruppe von Datensätze alle Werte von Spalten |
Können auf einzelne Spalten angewendet werden |
Liefern Datensätze aus externen Quellen, z.B. Access- Datenbank |
select sum(size) from files group by name |
|
SELECT CustomerID, CompanyName
FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0',
'C:\Program Files\Microsoft Office\OFFICE11\SAMPLES\Northwind.mdb';
'admin';'',Customers);
GO
|
|
AVG, COUNT, MAX, MIN, SUM, VAR, STDDEV |
|
OPENDATASOURCE, OPENROWSET |
Kontrollstrukturen
Anweisungsblock
Begin
{T-SQL Anweisung | anweisungsblock}
EndIF ... Then
IF boolscher_Ausdruck
T-SQL Anweisung | anweisungsblock
[ELSE T-SQL Anweisung | anweisungsblock ]case
CASE eingabeausdruck
when fall1 then ergebnisausdruck1
[{when fallN then ergebnisausdruckN}]
[ELSE else_ergebnisausdruck]
ENDwhile
while Boolscher_ausdruck
T-SQL Anweisung | anweisungsblockMittels der Anweisung break kann die While- Schleife vorzeitig beendet werden. Durch continue kann die Abarbeitung des Schleifenblocks vorzeitig beendet werden, und der nächste Schleifenzyklus wird eingeläutet.
Fehlerbehandlung
Jeder Ausnahme- bzw. fehlerhafte Zustand ist eine Fehlernummer zugeordnet. Neben den Fehlernummern gibt es noch einen sog. Schweregrad. Es handelt sich hierbei um eine Klassifizierung der Fehler.
|
Schweregrade |
Beschreibung |
|---|---|
|
1 bis 10 |
Statusmeldungen / Informationen |
|
11 bis 16 |
Benutzerdefinierte Fehlermeldungen |
|
17 bis 25 |
Hard und Softwarefehler |
Tritt bei einer T-SQL Anweisung ein Fehler auf, dann wird in der Systemvariabel @@ERROR eine Fehlernummer eingertragen. @@ERROR ist vom Typ Integer.
create proc del_artikel @artnr char[6]
as
delete from artikel where atrikelnr = @artnr
if @@error <> 0
return -1
else
return 0
goBenutzerdefinierte Fehler
Mittels der Anweisung RAISERROR kann ein benutzerdefinierter Fehler generiert werden. Die Fehlernummer sollte dabei stets größer 50000 sein, und der Schweregrad zwischen 11 und 18. Systemadministratoren können mittels RAISERROR darüber hinaus auch Fehler mit Schweregraden zwischen 19 und 25 generieren.
RAISERROR (<Fehlermeldung> | <Fehlernummer>, <Schweregrad>, <Status>)
Status ist eine beliebige Zahl zw. 1 und 127.
Soll die Fehlermeldung in das Windows- Ereignisprotokoll geschrieben werden um z.B. mittels der SQL- Server Agent Warnungen diese auszuwerten, dann muß die Option With Log an RAISERROR angehangen werden:
RAISERROR (<Fehlermeldung> | <Fehlernummer>, <Schweregrad>, <Status>) WITH LOG
try.. catch Blöcke
Analog in höheren Programmiersprachen kann ab SQL Server 2005 die Fehlerbehandlung über Try- Catch Blöcke abgewickelt werden. Achtung: Status und Infomeldungen führen zu keiner Verzweigung in den catch- block.
begin try
RAISERROR ('ich bin ein selbstdefinierter Fehler', 15, 2) WITH LOG
print('nach Raiseerror')
end try
begin catch
print( 'aus catch')
SELECT
ERROR_NUMBER() AS ErrorNumber,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_STATE() AS ErrorState,
ERROR_PROCEDURE() AS ErrorProcedure,
ERROR_LINE() AS ErrorLine,
ERROR_MESSAGE() AS ErrorMessage
print ERROR_MESSAGE()
end catchDDL
Datenbanken erstellen und löschen
create database datenbankname go
Eine Datenbank inklusiver aller in ihr enthaltenen Objekte wird gelöscht durch:
drop database datenbankname go
Schemas erstellen und Objekte hinzufügen
Der Bauplan aller Datenbankobjeke wird Schema gespeichert. SQLServer 2005 ermöglicht die unterteilung des Schemas in benannte Schemas. Der Zugriff auf die Datenbankobjekte kann für jedes beannte Schema individuell geregelt werden. Bennante Schemas sind ein Instrument Gliederung und Zugriffskontrolle.
Ein benanntes Schema wird angelegt durch:
create schema schemaname
In ein beanntes Schema können Datenbankobjekte verschoben werden durch:
alter schema schemaname transfer [name datenbankobjekt]
Tabellen erstellen
create table tabellenname ( spaltendeklaration | Einschräkung )
Tabellen Ändern
use geoinfo go alter table laender alter column ewz float go
Implementieren der Datenintegrität
Autoincrement
Für Primärschlüsselspalten ist es oft praktisch, die Datenbank selbst eindeutige Schlüssel beim Einfügen neuer Datensätze erzeugen zu lassen. Mittels der Eigenschaft IDENTITY kann im SQL- Server ein Zähler programmiert werden, dessen aktueller Zählerstand beim Einfügen einer neuen Zeile als Schlüsselwert genutzt wird. Nach dem Einfügen erhöht sich der Zähler automatisch um eine einstellbare Schrittweite.
Der erste Parameter von Identity gibt den Startwert an, und der zweite die Schrittweite.
create table kunde ( kd_nr int identity(100,1) not null, -- Kleinere Kundennummern als 100 werden nie erzeugt name varchar(100), vorname varchar(100), adresse varchar(255), primary key (kd_nr) ) go
Der zuletzt generierte Zählerstand kann mittels der Funktion IDENT_CURRENT('tabellenname') abgefragt werden:
insert into kunde(name, vorname) values('Hugendubel', 'Franz')
declare @id int
set @id = IDENT_CURRENT('kunde')Standardwerte
create table rechnung ( nr char(5)primary key, zahlungsart int default 1 ) go
Primary Key- Einschränkung
Definiert den Primärschlüssel einer Tabelle.
create table kennzeichen ( kz char(3), land varchar(100), primary key (kz) ) go
Unique – Einschränkung
Legt fest, das in einer Spalte jeder Wert eindeutig sein muß.
create table tanblock ( kontonr char(7), lfdnr int tan char(5) unique (tan) ) go
Foreign Key- Einschränkung
Definiert Fremdschlüssel in einer Tabelle
create table staedte ( stadt varchar(255) not null, kz_land char(3), flaeche float, ewz int, primary key(stadt, kz_land), foreign key(kz_land) references kennzeichen(kz) -- definiert kz_land als Fremdschlüssel ) go
Check- Einschränkung
Durch Check wird der Wertebereich für eine Spalte beschränkt.
create table mitarbeiter ( mnr int not null primary key, check(mnr >= 100), name varchar(255) not null, vorname varchar(255) not null, strasse varchar(255) not null, plz char(5) not null, check (plz like '[0-9][0-9][0-9][0-9][0-9]') ort varchar(255) not null, tel varchar(30), geschlecht char(1) not null, eingestellt_am date not null );
check- Einschränkungen können deaktiviert werden. Siehe dazu enterprise manager/datenbank/tebellen/tabelle-bearbeiten-> Kontextmenü der Spalte .
Datenintegrität ab- und anschalten
Enthält eine Tabelle z.B. Fremdschlüssel, dann erfolgt bei jedem Einfügen eines Datensatzes eine Prüfung, ob der Fremdschlüssel in der Mastertabelle existert. Sollen z.B. Große Datenmengen in diese Tabelle eingefügt werden, dann kann dieser Prozess durch die Prüfung der Integritätsregeln stark ausgebremst werden. In diesem Falle ist es sinnvoll, die Integritätsregeln für die betroffene Tabelle abzuschalten:
use dms go alter table words nocheck constraint all -- Alle Integritätsregeln für words werden abgeschaltet
Nach dem Massenkopieren in die Tabelle können die Regeln wieder durch folgenden Befehl eingeschaltet werden:
alter table words check constraint all -- Alle Integritätsregeln für words werden wieder eingeschaltet
Fremdschlüssel mit Left und Rigth- Outer- Joins prüfen
Nach Abschalten der Integritätsregeln können beim Einfügen diese Verletzt werden. Werden die Integritätsregeln wieder eingeschaltet, bleibt die Inkonsitenz erhalten. Mittels Outer Joins können solche Verletzungen der Integrität wieder aufgespürt werden.
Standards
Standardwerte können an Spalten gebunden werden für den Fall, daß ein neuer Datensatz eingefügt wird, jedoch für eine Spalte kein Wert vorgegeben wurde.
Regeln
Regeln dienen der Domäneintegrität. Durch sie können sichergestellt werden, das Werte
- Einem Muster entsprechen (Like ...)
- einer Liste von Werten entsprechen (In (...))
- in einen Bereich von Werten fallen (Between ... and ... )
Definition einer Regel:
CREATE RULE Name_der_RegelAS @Variablenname <WHERE- Klausel>
Beispiel
CREATE RULE R_FORM_EMAIL AS @email LIKE '%@%.[A-Z][A-Z]
Regeln können an Spalten oder an Datentypen gebunden werden. Dies kann mittels folgender gespeicherter Prozedur erfolgen:
sp_bindrule Name_der_Regel, Objname[, futureonly]
Nach dem Binden werden bei allen Datenänderungen am Objekt zuvor die Daten gegen die Regeln abgeprüft.
Um die Prüfung mit Regeln wieder zu unterbinden, müssen diese vom Objekt abgekoppelt werden wie folgt:
sp_unbindrule Objname [futureonly]
Benutzerdefinierte Datentypen
Indizes
Indizes dienen zur Beschleunigung des Zugriffes und zur Aufrechterhaltung der Integrität. Indizes werden durch B- Bäume realisiert:
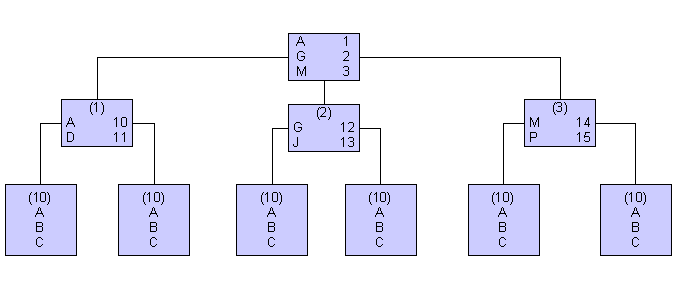
Indextypen
Gruppierte Indizes
In gruppierenden Indizes sind die Datensätze physikalisch geordnet. Die letzte Hierarchiestufe des B-Baumes sind die Seiten mit den Datensätzen selbst.
create clustered index ixWord on dbo.words
Folgende Bedingungen müssen bei gruppierenden Indizes beachtet werden:
- Es kann nur ein einziger gruppierter Index für eine Tabelle angelegt werden
- Die indizierten Spalten sollten eindeutig sein- nicht eindeutige Spalten werden intern mit einem versteckten Schlüüsel vom SQL- Server ergänzt, um eindeutigkeit wiederherszustellen – Durch Spalten mit Duplikaten erhöht sich damit unnötigerweise der Speicherplatz.
- Bei der Indexerstelung müssen mind. 120% der Tabellengröße vorhanden sein
- Nach der Indexerstellung ist der Speicherbedarf um etwa 5% der ursrpünglichen Größe angewachsen
- Der Schlüsselwert aus einem gruppierten Index wird in nicht gruppierten Indizes mitgeführt-> Große Schlüsselwerte aus gruppierenden Indizes führen zu Speicheintensiven nicht gruppierenden Indizes
- Gruppierende Indizes sollten, falls benötigt, als erste eingerichtet werden
Nicht gruppierte Indizes
Nicht gruppierte Indizes sind reine B- Bäume. Gegenüber gruppierten Indizes erfordern sie mehr Speicheplatz. Hingegen ist der Speicherbedarf bei der Erstellung geringer.
create nonclustered index ixWord on dbo.words(word)
Folgenden Bedingung müssen bei nicht gruppierenden Indizes beachtet werden:
- Es können bis zu 249 n.g. Indizes für eine Tabelle erstellt werden
Eindeutige Indizes
Eindeutige Indizes gehen davon aus, das keine Duplikate in den indizierten Spalten enthalten sind. Beim Durchsuchen einer Tabelle über einen solchen Index wird die Suche beim ersten Treffer abgebrochen.
create unique index ixUser on dbo.users(userid)
Soll verhindert werden, das in eine Spalten mit einem eindeutigen Index Duplikate eingefügt werden, muß die Option Ignore Dup Key gesetzt werden.
create unique index ixUser on dbo.users(userid) with ignore_dup_key
Wird trotzdem versucht, ein Duplikat einzufügen, ignoriert SQL- Server die Anweisung. Durch dieses Verhalten wirken eindeutige Indizes wie Integritätsregeln.
Mehrspaltige Indizes
Werden in Abfragen häufig bestimmte Spaltenkombinationen verwendet, so bietet es sich an, diese zu einem mehrspaltigen Index zusammenzufassen. Wenige mehrspaltige Indizes sind effizienter als viele einspaltigen Indizes.
create unique index ixWordFidPos on dbo.words(file_id, pos)
Achtung: Alle Spalten zusammen in einem mehrspaltigen Index dürfen nicht breiter als 900 Byte sein
Index anlegen
use [filesys-mko] go create nonclustered index ix_fnames on files (name) go
Index löschen
use [filesys-mko] go if exists(select * form sysindexes where name='ix_fnames' drop index files.ix_fnames go
Übung
- Auf der DMS- Datenbank wird zunächst ohne Index die Prozedur dms_search 'perl' ausgeführt. Analyse des Ausführungsplanes
- Gruppierenden Index auf Words.word anlegen
- dms_search 'perl' erneut ausführen und Ausführungsplan analysieren
Views
Unter einer View kann man sich eine virtuelle Tabelle vorstellen, deren Daten auf einer SQL- Abfrage basieren. Die in einer Sicht zusammengefassten Daten können mittels SELECT, INSERT, UPDATE, und DELETE bearbeitet werden.
Anlegen einer Sicht
create view name_der_sicht as select ...
Eine angelegte Sicht existiert solange, bis sie wieder gelöscht wird.
Arten von Sichten
|
Teilmenge von Tabellenspalten |
Teilmenge von Tabellenzeilen |
Verknüpfung von mindestens zwei Tabellen |
Aggregatinformationen |
|---|---|---|---|
|
Spalten mit sensitiven Daten können ausgeblendet werden. create view telbuch as select name, vorname, tel from tab_personal |
Ausblenden von Zeilen mit sensitiven Daten create view off_mitarb as select * from personal where beruf not like 'geheimagent' |
Vereinfachen des Zugriffs in normalisierten Datenbanken create view tab_personal as select * from personal join tel on personal.id = tel.id |
Vorverarbeitung von Daten create view hochrechnung as select partei, sum(stimmen) from auszaehlungen group by partei |
Löschen einer Sicht
drop view name_der_sicht
DML
Select ...
Qeuery Optimizer
Mittels der Select- Befehl können Teilmengen
aus der Datenbank extrahiert und verarbeitet werden. Dabei wird die
Herkunft der Daten, Einschränkungen, die sie erfüllen
deklariert. Der Datenbankserver erstellt aus der Deklaration
selbständig ein Programm, dessen Ausführung die gewünschte
Datenmenge liefert. Das Ergebnis wird Resultset
Die Select- Anweisung gliedert sich wie folgt auf:
Die Resultsets enthalten alle Spalten aller
betroffener Tabellen:
Durch die Liste von Spaltenoperationen wird das
Format des Resultset bestimmt. Im einfachsten Fall können alle
Spalten der ausgewählten Datensätze angezeigt werden
Spaltenoperationen werden in aggregierende und
nicht aggregierende unterscheiden:
Aggregierende Spaltenoperationen bilden die Werte von 1- N Zeilen
innerhalb einer Spalte auf einen Wert ab:
Nicht aggregierende Spaltenoperationen bilden 1-N
Werte innerhalb einer Zeile auf einen Wert ab:
Das Ergebniss einer Select- Abfrage ist ein
Resultset, bestehend aus Tabellenzeilen. Das verschiedene
Tabellenzeilen dabei identische Inhalte liefern, ist nicht
ausgeschlossen. Durch die Distinct Dierektive wird das
Resultset in seinem Umfang so reduziert, daß jede Tabellenzeile
einen einmaligen Inhalt innerhalb des Resultsets besitzt:
In der where -
Klausel wird ein Filterausdruck definiert, den alle Zeilen des
Resultsets erfüllen müssen. Der Filterausdruck entsteht
durch Verknüpfung von Vergleichen und Prädikaten mittels
logischer Operatoren:
Durch Group by wird ein Resultset bezüglich
der Zeilen in disjunkte Teilmengen gegliedert. Die Teilmengen werden
als Gruppen bezeichnet. Innerhalb einer Gruppe hat eine
Auswahl von Spalten für alle Zeilen immer denselben Wert. Diese
Spaltenauswahl wird auch als Gruppenschlüssel bezeichnet
So wie die where Klausel einen Filterausdruck
definiert, den alle Zeilen erfüllen müssen, die in das
Resultset einfließen, definiert die Having- Klausel einen
weiteren Filterausdruck, den alle Gruppen erfüllen müssen
im Resultset.
Der Sinn von Having wird deutlich, wenn der
Abfrageprozess, der zu den Gruppen führt, genauer betrachtet
wird:
Phase
Aktionen
ALIGN=CENTER STYLE="font-weight: normal; widows: 4">
1
Datensätze aus den Quelltabellen laden
ALIGN=CENTER STYLE="font-weight: normal; widows: 4">
2
Datensätze entfernen, die Where
Filterausdruck nicht erfüllen
ALIGN=CENTER STYLE="font-weight: normal; widows: 4">
3
Gruppieren bezüglich Group by
ALIGN=CENTER STYLE="font-weight: normal; widows: 4">
5
Pro Gruppe Spatenaggregate aus Select berechnen
ALIGN=CENTER STYLE="font-weight: normal; widows: 4">
6
Gruppen entfernen, die Having Filterausdruck
nicht erfüllen
Beispiel:
Subselect sind ein Feature, das nicht jeder
Datenbankserver mitbringt. TSQL kann Subselects !
Durch Subselect können aus einer Select-
Abfrage weitere Select- Abfragen gestartet werden. Um z.B. die größte
Datei in einer Tabelle zu bestimmen, die Dateien und ihren
Speicherplatzverbrauch auflistet, muss zuerst die maximale Dateigröße
bestimmt werden. Mit diesem Wert kann dann der Datensatz gesucht
werden, der diesen Speicherplatzverbrauch hat:
Mittels Subselect können beide Schritte in einer einzigen
Select- Anweisung zusammengefasst werden. Variablen werden nicht mehr
benötigt:
In seltenen Fällen ist es sinnvoll, in einer
Sitzung Ergebnisse von Abfragen zwischenzuspeichern, um in weiteren
Abfragen auf diese zurückzugreifen. Dies hat aber den Nachteil,
das der Server hierdurch massiv belastet wird ! In jedem Fall sollte
geprüft werden, ob durch Views oder Subselects kein alternativer
Lösungsweg besteht.
Grundidee von relationalen Datenbanken ist die
Betrachtung von Datenbanken als Mengen und Operationen, wie sie durch
die mathematische Mengenlehre definiert sind.
Gegeben sei z.B. eine Menge von Himmelskörpern
(Sonne, Jupiter, Erdmond, Ceres, …) und eine Menge von
Gewichtsangaben der Himmelskörper, dargestellt in Vielfachen der
Erdmasse (1 [=Erde], 0,0123 [=Erdmond], 332981 [=Sonne], …).
Auf diesen beiden Mengen kann das sog. Kreuzprodukt
gebildetet
werden, indem jedes Element der einen Menge mit jedem Element der
anderen Menge kombiniert wird. Hat z.B. die Menge der Himmelskörper
n
Elemente, und die Menge der Erdmassen
m
Elemente, dann hat das Ergebnis des Kreuzproduktes
m
* n
Elemente.
In
der Relationalen Datenbank werden Mengen durch Tabellen dargestellt.
Das Kreuzprodukt entsteht durch eine spezielle
Select-Anweisung, in deren From- Klausel
entweder mehrere Tabellen durch den Komma, oder durch den
CROSS JOIN Operator kombiniert werden:
Bedingt durch Normalisierung bei der
Datenmodellierung verteilen sich die Informationen zu Entities auf
viele Tabellen. Um alle Daten eines Entity wieder in einem Stück
zu bekommen, ist ein verknüpfen der Tabellen nötig (Inner
Join).
Das Prinzip der Verknüpfung aus
mengentheoretischer Sicht besteht im bilden des Kreuzproduktes
zwischen den durch zwei Tabellen dargestellten Mengen, und dem
anschließenden Herausfiltern all jener Tupel, bei denen
Schlüssel und Fremdschlüssel übereinstimmen. Folgendes
Bild demonstriert das Verfahren. Schlüssel und Fremdschlüssel
werden dabei durch die astrologischen Symbole der Himmelskörper
ausgedrückt.
Folgende Übung erklärt schrittweise den
Inner Join.
Beim
Join einer Tabelle mit einer Tabellenwertfuktion können als
Parameter der Tabellenwertfunktion nur Konstanten oder TSQL-
Variablen eingesetzt werden. Folgender Join liefert nur die Trabanten
der Sonne:
Mittels des CROSS APPLY Operators
kann diese Einschränkung überwunden werden. Parameter
können hier an Attribute von Datensätzen gebunden werden,
welcher der linke Teil von CROSS APPLY liefert. Folgender CROSS APPLY
liefert die Trabanten der Sonne, der Planeten usw.
Mittels Select Into werden neue Tabellen
erstellt.
Die From- Klausel einer Select Anweisung kann so
formuliert werden, daß auf Tabellen von Datenbanken außerhalb
des aktuellen Datenbankkontextes (use DBName) erreichbar sind.
Dazu ist der Datenbankname dem Besitzernamen voranzustellen:
Auch über Servergrenzen hinaus sind Selects
möglich. Dazu müssen die fernen Server zuerst als
Verbindungsserver definiert werden. Dies geschieht mit der
gespeicherten Prozedur sp_addlinkedserver.
Nach dieser Registrierung sind auch
Datenbankobjekte aus anderen Servern erreichbar, indem der
Servernamen dem Namen des Datenbankobjekts vorangestellt wird:
Durch UNION können die Ergebnisse mehrerer
Select- Abfragen zu einem Resultset zusammengefasst werden. Dabei
müssen alle Teilselects die gleiche Spaltenliste zurückgeben.
Beispiel:
Mittels dieser Anweisung kann eine Liste aus
Detaildaten und Zusammenfassungen erstellt werden. Soll z.B. für
die Beispieldatenbank DMS eine Liste mit den Inhalten aller
Verzeichnisse, wobei zu jedem Verzeichnis die Größe in
Byte auszugeben ist, dann kann dies durch folgenden Compute- By-
Anweisung erreicht werden:
Achtung: Ein Compute- By- Select muß immer eine
Order
By
– Klausel enthalten
Eine Menge von Datensätzen kann in Gruppen
und diese wiederum in Untergruppen unterteilt werden. Aus Gruppen
werden in SQL gewöhnlich durch Aggregatfunktionen verdichtete
Informationen gewonnen. Zusammenfassungen dazu werden mittels der
Rollup- Funktion automatisch hinzugefügt. Bsp:
Ergebnis:
Die Zusammenfassung ist ein neuer Datensatz im Resultset, der in der
gruppierten Spalten den Wert Null enthält.
Zusammenfassungen
mittels Cube:
Ergebnis:
Jede Zeile des Rowsets wird in ein <row ... />
Element verpackt. Im Element wird für jede Spalte ein Attribut
mit Attributname = Spaltenname erzeugt. Der Attributwert entspricht
Spaltenwert in der entsprechenden Zeile.
Ergebnisse aus Abfragen können mit dieser speziellen SQL-
Anweisung in einer Tabelle abgespeichert werden.
Mittels Insert Into können einer
Tabelle neue Zeilen hinzugefügt werden. Eine Variante ermöglicht
das Einfügen einer Zeile:
Eine Zweite Variante ermöglicht
es, die Daten aus einer zweiten Tabelle zu entnehmen und in der
Zieltabelle einzufügen:
Für Tabellen, deren Schlüssel
automatisch erzeugt werden, ist der Wert des neuen Schlüssels
nach dem Einfügen oft von interesse. Dieser kann auf zwei Arten
bestimmt werden.
Mit dem Output- Zusatz in einer Insert
Anweisung können die eingefügten Daten als Resultset
zurückgegeben werden:
Mit dem zusatz Into
Sollen alle Zeilen einer Tabelle gelöscht
werden, dann kann dies mit einer speziellen Form der
delete-
Anweisung erfolgen:
Dabei können alle Löschaktionen für jede Zeile im
Transaktionsprotokoll protokolliert werden, was die Ausführungszeit
und den Resourcenverbrauch auf dem Server erhöht. Ist eine
Protokollierung der Löschaktionen pro Zeile nicht erforderlich,
dann die Truncate Table- Anweisung eingesetzt werden. Durch sie wird
die Ausführungszeit und den Resourcenverbrauch auf dem Server
beim löschen aller Zeilen minimiert.
Die Benutzer konkurrieren beim Zugriff auf die
Datensätze in den Tabellen einer Datenbank auf einem
Datenbankserver. Durch Sperren wird dabei verhindert, dass
sich mehrere Datensatzaktualisierungen überlagern und es so zu
Datenverlusten und Inkonsistenzen kommt.
Folgende Arten von Sperren gibt es: Lesesperre Exklusive Sperre Aktualisierungssperre Beabsichtigte Sperre
Hat eine Objekt eine Lesesperre, dann kann
diese nur von den Transaktionen ausgelesen werden, die die
Lesesperre gesetzt haben. Parallele Lesevorgänge sind
möglich, jedoch keine Aktualisierungen und Löschvorgänge.
Ein Objekt mit einer exklusiven Sperre kann nur
von der Transaktion bearbeitet werden, die die Sperre gesetzt hat.
Alle anderen Transaktionen wird der Zugriff auf das Objekt
verwehrt.
Transaktionen, bei denen im ersten Schritt die
Datensätze durchsucht (Lesesperre) und im zweiten Schritt die
Datensätze geändert werden (Exklusive Sperre), setzten
Aktualisierungssperren um Deadlocks zu vermeiden. Diese
überspannen den Lese- als auch den Aktualisierungsvorgang.
Zeigen an, das demnächst ein Objekt mit
einer Sperre belegt wird.
Es können folgende Objekte gesperrt werden:
Tabellenzeile, Seite (8KB), Block (a 8 Seiten) und Tabelle.
Achtung: Eine Tabellenzeile kann sich über
mehrere Seiten und Blöcke erstrecken. Umgekehrt kann eine Seite
oder ein Block mehrere Zeilen enthalten.
Das Setzten der Sperren erfolgt beim Bearbeiten
der konkurrierenden Datenbankzugriffe durch den SQL- Server in der
Regel automatisch. Dabei wird die notwendige Sperre mit möglichst
optimaler Ausdehnung (Zeile, Seite, Block oder Tabelle) gewählt.
Die Ausdehnung wird aus den Statistiken des Ausführungsplanes
abgeleitet. In einem Fall könnten Sperren auf Zeilenebene
sinnvoll sein (viel Parallelität, aber auch viel
Ressourcenverbrauch beim Sperren vieler Zeilen), im anderen Sperren
auf Tabellenebene (keine Parallelität, minimalen
Ressourcenverbrauch da nur eine Sperre benötigt wird).
Sollten bei der Abarbeitung von Transaktionen
Deadlocks auftreten, kann mit dem manuellen setzten von Sperren
eingegriffen werden. Dies erfolgt durch sogenannte Sperrhinweise
hinter den Tabellennamen.
Es sind folgende Sperrhinweise möglich:
Sperrhinweis Details ROWLOCK
Die Ausdehnung von Sperren wird auf Zeilen
eingeschränkt
PAGLOCK
Die Ausdehnung von Sperren wird auf Seiten
eingeschränkt
TABLOCK
Die Sperren betreffen immer die gesamte
Tabelle.
TABLOCKX Belegt eine Tabelle mit einer exklusiven Sperre NOLOCK READUNCOMMITTED
Es werden nie Sperren auf die Tabelle
angewendet. Dadurch können Datensätze von einer
Transaktion gelesen werden, während eine zweite sie noch
bearbeitet (Dirty Reads).
READPAST
Die gesperrten Zeilen von aktualisierenden
Transaktionen werden durch die lesende Transaktion übersprungen.
Im Resultset fehlen diese dann, was zu Fehlern bei der Auswertung
führen kann.
REPEATEBLEREAD
Lesesperren auf einer Tabelle werden erst
aufgehoben, wenn die lesende Transaktion beendet wird. Update und
Delete ist auf der Tabelle nicht möglich, wohl aber Insert.
HOLDLOCK SERIALIZABLE
Lesesperren werden erst aufgehoben, wenn die
anfordernde Transaktion beendet ist. Insert- Operationen auf den
geperrten Objekten sind blockiert.
Definition Transaktion
Eine Transaktion ist eine Folge von T-SQL
Anweisungen, die mit dem Befehl Begin Transaction
eingeleitet, und mit den Befehlen Commit Transaction
oder Rollback Transaction beendet werden.
Werden alle Anweisungen innerhalb einer
Transaktion erfolgreich ausgeführt, dann muß die
Tranwsaktion mit Commit Transaction abschließen, und
die durch Anweisungen bewirkten Datenänderungen werden
dauerhaft in der Datenbank übernommen.
Andernfalls muß die Transaktion durch
Rollback Transaction beendet werden. In diesem Falle
werden alle Datenänderungen wieder zurückgenommen, und
die Datenbank befindet sich in dem Zustand wie vor der Ausführung
der Transaktion.
Definition ACID
ACID ist ein Akronym und steht für die
vier Anforderungen, die eine Transaktion erfüllen muß:
Atomicity (Unteilbarkeit),
Consistency (Konsistenz), Isolation
(Isolation), Durability (Dauerhaftigkeit).
Unteilbarkeit bedeutet, das ein Transaktion
entweder erfolgreich durchgeführt wird (Commit), oder nach
Abbruch das System sich wieder im Zustand unmittelbar vor Beginn der
Transaktion befindet (Rollback).
Befindet sich die Datenbank vor der Ausführung
einer Transaktion in einem Konsitenten Zustand, dann wird sie es auch
nach der Transaktion wieder sein.
Isolation beschreibt, wie unabhängig parallel
ablaufende Transaktionen voneinander sind.
Kann eingestellt werden über
die Option SET trANSACTION ISOLATION LEVEL.
Wird ein Commit ausgeführt, dann sind
die Datenänderungen, auch bei plötzlich auftretenden
Systemfehlern definitiv in die Datenbank zu übernehmen.
Im expliziten Modus werden Transaktionen durch
spezielle Anweisungen im Script eröffnet und abgeschlossen.
Beispiel:
Folgende Anweisungen sind innerhalb von
Transaktionen verboten:
Innerhalb einer Transaktion können
Sicherungspunkte gesetzt werden. Sicherungspunkte stellen
Markierungen im Transaktionsprotokoll dar. Ein Rollback kann in
seiner Wirkung eingeschränkt werden, indem im Rollback- Befehl
der Name des Sicherungspunktes angegeben wird, bis zu dem der
Rollback erfolgen soll.
Jede Anweisung, die Daten ändert, ist
automatisch in eine Transaktion eingeschlossen. Die Anweisung:
wird vom Server automatisch in eine Transaktion wie folgt verpackt:
Werden eine Vielzahl von Datenänderungsanweisungen in Folge
abgesetzt, so kann die Serverlast minimiert werden, indem alle in ein
explizite Transaktion verpackt werden wie folgt:
Anstatt 9 Einträge, wie es im Autocommit- Modus der Fall wäre,
erfolgen jetzt nur noch 5 Einträge im Transaktionsprotokoll.
Implizite Transaktionen werden im SQL- Server
bereitgestellt, um ANSI- Konformität zu erreichen. Der Implizite
Modus muss mit folgender Anweisung aktiviert bzw. deaktiviert werden:
Folgende Anweisungen müssen dann mittels COMMIT trAN oder
ROLLBACK trAN quittiert werden:
Für alle in einer Transaktion
eingeschlossenen Abfragen können Sperrhinweise definiert werden
durch den Transaction Isolation Level. Dieser wird gesetzt durch folgendes Kommando
Der Standardwert ist
READ
COMMITED.
Die Isolationsstufen im
Einzelnen:
Isolationsstufe Details READ COMMITED
Nur Daten werden gelesen, die zuvor mit einer
Lesesperre belegt werden konnten. Dirty Reads sind nicht möglich.
READ UNCOMMITED
Es werden keine Sperren gesetzt. Dirty Reads
sind möglich
REPEATABLE READ
Lesesperren werden erst nach dem Ende der
Transaktion aufgehoben. Wiederholte Select- Abfragen innerhalb
einer Transaktion führen zu identischen Resultsets, wenn
zwischen diesen keine Änderungsoperationen innerhalb der
Transaktion vorgenommen wurden. Änderungsoperationen andere
Transaktionen sind während der gesamten Verarbeitung einer
Transaktion blockiert.
SERIALIZABLE
Wie REPEATABLE READ, zusätzlich werden
noch Einfügeoperationen anderer Transaktionen verhindert.
Gespeicherte Prozeduren
können Skalare oder Resultsets ausgeben. Skalare Werte werden
über die Parameterliste als output- Parameter ausgegeben.
Eine Gepeicherte Prozedur kann auch einen Integerwert zurückgeben.
Mit benutzerdefinierte Funktionen kann der
Datenbankentwickler die Funktionalität von TSQL erweitern. Es
gibt drei Typen von benutzerdefinierten Funktionen:
Liefern einen Skalaren Wert zurück. Können
in Ausdrücken unbeschränkt eingesetzt werden.
Eine besonders einfache Funktion liefert nur eine
Konstante: die Erdmasse in Kg. Die Funktion ist Parameterlos
Die
Folgende Funktion rechnet den Speicherbedarf von Byte in Kilobyte um.
Dazu hat sie einen Parameter.
Liefern
eine Tabelle als Wert zurück. Können in einem Select Befehl
überall dort eingesetzt werden, wo auch Subselects zulässig
sind:
Trigger sind spezielle gespeicherte Prozeduren,
die gestartet werden, wenn Datenzeilen einer Tabelle mittels DELETE,
INSERT oder UPDATE geändert werden.
Wurden mehrere After Trigger definiert, dann
werden sie in einer durch den Zufall bestimmten Reihenfolge
ausgeführt. Mittels der gespeicherten Prozedur
sp_settriggerorder kann davon abweichend ein After- Tirgger
als erster bzw. als letzter auszuführender definiert werden.
Pro insert, update
und delete - Anweisung kann ein Instead- Of- Trigger definiert
werden. Damit wird pro Aktualisierung immer nur genau ein Instead- Of
Trigger aufgerufen.
In Triggern kann auf die beiden Spezialtabellen
deleted und inserted zugegriffen werden. Ihre
Struktur entspricht 1:1 der Struktur der Tabelle oder Sicht, für
die sie implementiert wurden.
Wird eine Zeile mittels
DELETE gelöscht, dann enthält deleted die Kopie der
gelöschten Zeile.
Werden neue Zeilen
einer Tabelle hinzugefügt, dann stehen diese als Kopie in der
Tabelle inserted.
Wird eine Zeile durch
Update geändert, dann steht die ursprüngliche Zeile vor der
Änderung in der Tabelle deleted und die neue geänderte
Zeile in der Tabelle inserted.
Einsatz
Trigger werden implementiert zur Durchsetzung
der referentiellen- und Datenintegrität sowie der Kapselung
von Geschäftsregeln.
temporäre
Tabellen
Für temporäre Tabellen können
keine Trigger erstellt werden
Resultsets
Trigger dürfen keine Resultsets
zurückliefern. Select- Anwiesungen in Triggern sollten in
if
exists(...)
gekapselt werden.
Verschlüsselung/Sicherheit
Mit der Option with encryption kann die
definition der Trigger in der Tabelle syscomments verschlüsselt
werden.
verbotene
Anweisungen
Folgende Anweisungen dürfen in
Triggerimplementierungen nicht auftreten:
alter table, alter
database, truncate table, grant, revoke, reconfigure, load
database, load transaction, update statistics, select into,
alle
disk -Anweisungen
rollback
Rollbacks von Transaktionen in Triggern können
zu unerwarteten Ergebnissen führen
Implementieren Sie einen Trigger, der beim
Einfügen in die Tabelle Users DMS einen Eintrag in der Tabelle
UpdateLog durchführt
Cursor sind Hilfsmittel, mit denen von einer
prozeduralen Programmiersprache Datensätze aus einer
Ergebnismenge nacheinander auslesbar sind.
Das Ergebnis ist ein Resultset, bestehend aus (
Database_name,
Database_size,
NULL)
+-----------------+
Select- Befehl --->| |
| Datenbankserver |
{Resultset} <---| |
+-----------------+
select <Liste von Spaltenoperationen> | *
from <Liste der Datenquellen>
where <Filterausdruck, den die ausgewählten Zeilen erfüllen müssen>
group by <Liste der Spalten, bezüglich der zu gruppieren ist>
having <Filterausdruck, den alles ausgewählten Gruppen erfüllen müssen>
order by <Liste der Spalten, bezüglich der zu sortieren ist>
Select *
use dmsmin
go
select *
from data.FileInfos
Select <Liste von Spaltenoperationen>
Spaltenoperationen
|
+-------------+-------------+
| |
aggregierende nicht aggregierende
-- Gesamter Speicherplatzverbrauch mittels sum- Aggregatfunktion berechnen
select Sum(SizeInBytes)
from data.FileInfos
-- Größe der kleinsten Datei bestimmen
select Min(SizeInBytes)
from data.FileInfos
-- Größe der größten Datei bestimmen
select Max(SizeInBytes)
from data.FileInfos
-- Durchschnittliche Dateigröße bestimmen
select Avg(SizeInBytes)
from data.FileInfos
-- Wie viel Zeilen hat die Tabelle FileInfos
select count(*) As [Anzahl + Zeilen]
from data.FileInfos
-- Auswahl von Spalten (Spaltenfunktionen sind 1:1 Abbildungen)
select [name], ext, SizeInBytes
from data.FileInfos
–- Zusammenfassen von Dateiname und Extension zum vollständigen Dateiname
–- Umrechnen der SizeInBytes in Kilobyte. Das Ergebnis wird auf 3 Nachkommastellen gerundet
select [name] + ext As [Filename], round(Cast(SizeInBytes as float)/1024, 3) as SizeInKB
from data.FileInfos
–- Position des Punktes innerhalb des Zeichenkettenwertes der Spalte Name mittels
–- charindex- Spaltenoperation
select charindex('.', [name])
from data.FileInfos
Select distinct – Entfernen von Dubletten
select distinct ext from data.FileInfos
Select ... where – Auswahl der Zeilen
use dmsmin
go
–- Einschränken der Datensätze auf Dateien kleiner 1 Kilobyte
select [name], SizeInBytes
from data.FileInfos
where SizeInBytes < 1024
-- Einschränken der Datensätze auf html und xml- Dateien kleiner 1 Kilobyte
select [name], SizeInBytes
from data.FileInfos
where SizeInBytes < 1024 and ext = 'htm' or ext = 'xml'
-- Einschränken der Datensätze auf html und xml- Dateien kleiner 1 Kilobyte
select [name], SizeInBytes
from data.FileInfos
where SizeInBytes < 1024 and (ext = '.htm' or ext = '.xml')
-- Einschränken der Datensätze auf html und xml- Dateien kleiner 1 Kilobyte
select [name], SizeInBytes
from data.FileInfos
where SizeInBytes < 1024 and (ext like '.htm%' or ext = '.xml')
-- Einschränken der Datensätze auf html und xml- Dateien kleiner 1 Kilobyte
select [name], SizeInBytes
from data.FileInfos
where SizeInBytes < 1024 and (ext in ('.htm', '.html', '.xml'))
-- Einschränken der Datensätze auf Dateien kleiner 1 Kilobyte, die weder html noch xml sind
select [name], SizeInBytes
from data.FileInfos
where SizeInBytes < 1024 and (ext not in ('.htm', '.html', '.xml'))
Group By – Resultset in Gruppen gliedern
use dmsmin
go
-- Gesamter Speicherplatzverbrauch
select sum(SizeInBytes)
from data.FileInfos
-- Speicherplatzverbrauch pro Dateityp
select ext, sum(SizeInBytes)
from data.FileInfos
group by ext
-- Speicherplatzverbrauch pro Dateityp
select ext, sum(SizeInBytes) as [Size]
from data.FileInfos
group by ext
order by [Size] asc
-- Speicherplatzverbrauch pro Dateityp
select ext, sum(SizeInBytes) as [Size]
from data.FileInfos
group by ext
order by [Size] desc
-- Gruppieren: Wieviel Daten wurden pro Monat produziert
select year(mtime) as Jahr, Month(mtime) as Monat, Sum(SizeInBytes)/1024.0 as SizeInKB
from data.fileinfos
where SizeInBytes/1024.0 > 10 and (mtime between '1.1.2004' and '31.12.2005')
group by Year(mtime), Month(mtime)
order by Year(mtime), Month(mtime)
Having – Gruppen filtern
SELECT ext, SUM(SizeInBytes) AS SumSizeInBytes
FROM data.FileInfos
GROUP BY ext
having SUM(SizeInBytes) between 100000 and 200000
ORDER BY SumSizeInBytes DESC
Subselects
use dmsmin
go
Declare @MaxSize as BigInt
-- 1) Größe der größten Datei bestimmen
select @MaxSize = Max(SizeInBytes)
from data.FileInfos
-- 2) Name der größten Daten bestimmen
select [name], SizeInBytes
from data.FileInfos
where SizeInBytes = @MaxSize
-- Name der größten Daten
select [name], SizeInBytes
from data.FileInfos
where SizeInBytes = (select Max(SizeInBytes)
from data.FileInfos)
go
Temporäre Tabellen
use dmsmin
go
drop table #sizepertype
go
-- Liste des Speicherplatzverbrauches pro typ in temp- Tabelle speichern
select ext, Sum(SizeInBytes)/1024.0 as SumSizeInKB
into #SizePerType
from data.FileInfos
group by ext
order by SumSizeInKb
select * from #SizePerType
-- Wie groß ist der Anteil des Speichers pro Typ in bezug auf den Gesamtverbrauch
select ext, Round(100 * SumSizeInKB / (select Sum(SizeInBytes)/1024.0 from data.FileInfos), 1) as [Anteil an Gesamt]
from #SizePerType
Cross Join

|Himmelskörper| == n, |Erdmassen| == m => |Himmelskörper| x |Erdmassen| == m*n
use master
go
drop database u3Joins
go
create database u3Joins
go
use u3Joins
go
create table HK (
Name varchar(255)
)
insert into HK values('Sonne')
insert into HK values('Mond')
create table EM (
Masse float
)
insert into EM values(332981)
insert into EM values(1)
insert into EM values(0.0123)
go
-- Natürlicher Join (math.: Kreuzprodukt)
select Name, Masse
from HK, EM
-- Alternativ
select Name, Masse
from HK CROSS JOIN EM
Inner Join

create table HK (
ID int primary key,
Name varchar(255)
)
insert into HK values(1, 'Sonne')
insert into HK values(3, 'Mond')
create table EM (
ID int identity,
HK_ID int foreign key references HK(ID),
Masse float
)
insert into EM (HK_ID, Masse) values(1, 332981)
insert into EM (HK_ID, Masse) values(3, 0.0123)
-- Um einen Datensatz für die Erde, zu der es keinen Masterdatensatz in HK gibt,
-- einzufügen, müssen kurzfristig Einschränkungen abgeschaltet werden
alter table EM nocheck constraint all
insert into EM (HK_ID, Masse) values(2, 1)
alter table EM check constraint all
go
-- Inner Join (math.: Einschränkung des Kreuzprodukts durch ein Filterkriterium => Relation)
select 'inner Join', Name, Masse
from HK inner join EM on HK.ID = EM.HK_ID
-- Alternativ
select 'alternativ mit ,', Name, Masse
from HK, EM
where HK.ID = EM.HK_ID
-- Inner Joins sind Kommutativ
select 'kommutativ!', Name, Masse
from EM inner join HK on HK.ID = EM.HK_ID
Outer Join


-- Outer Joins
-- sind nicht Kommutativ !
select 'left outer', Name, Masse
from HK left outer join EM on HK.ID = EM.HK_ID
select 'right outer', Name, Masse
from HK right outer join EM on HK.ID = EM.HK_ID
Cross Apply
Select H.Name as [Zentralkörper],
T.ZentralkoerperTyp as [Typ],
H.Masse_in_kg as Masse,
T.Trabant as Trabant,
T.Umlaufdauer_Tage,
T.TrabantTyp as [Typ Trabant]
from [dbo].[HimmelskoerperTab] as H Join dbo.Trabanten_von('Sonne') as T on H.ID = T.ZentralID
order by Masse desc, Umlaufdauer_Tage

Select H.Name as [Zentralkörper],
T.ZentralkoerperTyp as [Typ],
H.Masse_in_kg / dbo.Erdmasse() as Masse,
T.Trabant as Trabant,
T.Umlaufdauer_Tage,
T.TrabantTyp as [Typ Trabant],
T.Trabantmasse / dbo.Erdmasse() as Trabantmasse
from [dbo].[HimmelskoerperTab] as H CROSS APPLY dbo.Trabanten_von(H.Name) as T
order by Masse desc, Umlaufdauer_Tage
Select ... into <Tabellenname>...
Select über Datenbankgrenzen
use dms
go
select name from dms2.dbo.dirs -- Zugreifen auf die Dirs- Tabelle in dms2
go
Select über Servergrenzen
exec sp_addlinkedserver 'shuttle\msde2'
use dms
go
select * from [shuttle\msde2].dms.dbo.dirs
go
Select ... UNION
-- UNION
-- Bestimmen aller Dateien, die das Wort 'perl' enthalten. Die Daten sind
-- auf zwei Serverinstanzen verteilt (local und trAC19\MSDE). Durch Union werden
-- beide Teilergebnisse wieder zusammengeführt
select file_id, pos
from dms.dbo.words
where word like 'perl'
UNION
select file_id + 100000, pos
from [trAC19\MSDE2].dms.dbo.words
where word like 'perl'
order by file_id, pos
go
Compute By
use dms
go
select dirs.[name], files.[name], [size]
from dirs join files on dirs.dir_id = files.dir_id
order by files.dir_id
compute sum([size]) by files.dir_id
Superaggregate (Rollup und Cube)
-- Berechnen der Verzeichnisgrößen + Gesamtgröße der Doku- Webseite
use DMS
go
select dirs.[name], round(sum(files.size)/(1024.0*1024.0), 3) as DirSize
from dirs join files on dirs.dir_id = files.dir_id
where dirs.[name] like '%\trac\projekt\%\trac_neu\wissen\%'
group by dirs.[name]
with rollup
name DirSize
---------------------------------------------------------------------------- -----------------------------------
d:\trac\projekt\www\trac_neu\wissen\datenbanken 1.481000000000
d:\trac\projekt\www\trac_neu\wissen\datenbanken\ms-sql-server 2.816000000000
d:\trac\projekt\www\trac_neu\wissen\datenbanken\solar_pics .990000000000
d:\trac\projekt\www\trac_neu\wissen\datensicherheit 4.678000000000
d:\trac\projekt\www\trac_neu\wissen\dot-net 5.795000000000
d:\trac\projekt\www\trac_neu\wissen\einfuehrung 1.348000000000
d:\trac\projekt\www\trac_neu\wissen\html 2.008000000000
d:\trac\projekt\www\trac_neu\wissen\html\php-mysql .103000000000
d:\trac\projekt\www\trac_neu\wissen\netzwerk 5.098000000000
d:\trac\projekt\www\trac_neu\wissen\netzwerk\router .660000000000
d:\trac\projekt\www\trac_neu\wissen\netzwerk\router\router .028000000000
d:\trac\projekt\www\trac_neu\wissen\pc-technik 1.621000000000
d:\trac\projekt\www\trac_neu\wissen\programmieren 2.029000000000
d:\trac\projekt\www\trac_neu\wissen\programmieren\cpp 2.049000000000
d:\trac\projekt\www\trac_neu\wissen\programmieren\cpp\com .129000000000
d:\trac\projekt\www\trac_neu\wissen\programmieren\cpp\projekt_browser .138000000000
d:\trac\projekt\www\trac_neu\wissen\programmieren\versionen .076000000000
NULL 31.048000000000
-- Berechnen der Verzeichnisgrößen + Gesamtgröße der Doku- Webseite
use DMS
go
select dirs.[name], files.ext, round(sum(files.size)/(1024.0*1024.0), 3) as DirSize
from dirs join files on dirs.dir_id = files.dir_id
where dirs.[name] like '%\trac\projekt\%\trac_neu\wissen\%'
group by dirs.[name], files.ext
with cube
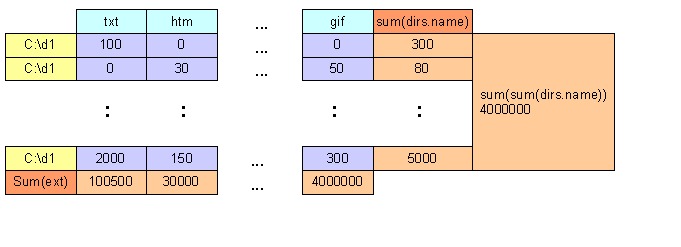
Select XML- Ausgabe
Mode RAW
SELECT * FROM dirs FOR XML RAW
go
<row name="c:/" dir_id="0" superdir_id="-1"/>
<row name="winnt" dir_id="1" superdir_id="0"/>
...
Mode Auto
select dirs.name, files.name from dirs inner join files on dirs.dir_id = files.dir_id FOR XML AUTO
go
<dirs name="datenbanken">
<files name="DATENBANKEN_GRUNDBEGRIFFE"/>
<files name="sonnensystem"/>
...
</dirs>
...
Insert Into
Insert Into dbo.users ([user], [password]) values('Hugo', 'bo55') Insert Into dbo.users ([user], [password])
select [users], [password]
from [shuttle].dms.dbo.users -- Daten aus der users- Tabelle aus einem Zweiten Server
-- entnehmen
Bestimmen der neuen Id beim Einfügen in eine Tabelle mit
Identity- Schlüsselspalte
insert into dbo.EventLog (msg)
output inserted.id
values ("Eine neue Meldung") Declare @line Table(id int)
insert into dbo.EventLog (msg)
output inserted.id into @line
values ("Eine neue Meldung")
select @id = id from @line
Delete from ...
-- Alle Zeilen aus der Tabelle data.FileInfos löschen, die xml- Dateien im Dateibaum beschreiben
delete from data.FileInfos where ext = '.xml'
go
trUNCATE TABLE
-- Alle Zeilen aus der Tabelle data.FileInfos löschen
delete from data.FileInfos
go
-- Alle Zeilen aus der Tabelle data.FileInfos löschen ohne Protokollierung
truncate table data.FileInfos
go
Update ...
use geoinfo
go
update laender set ewz = 3.4 where land like 'Albanien'
go
Tabellensperren
Manuelles setzten von Sperren
select * from dbo.Artikel (TABLOCKX) –- Sperrhinweis TABLOCKX= exklusive Tabellensperre setzten
Transaktionen
Unteilbarkeit
Konsitenz
Isoloation
Dauerhaftigkeit
Transaktionsmodi
Expliziter Modus
BEGIN trANSACTION <Transaktionsname>
...
if <alles ok>
COMMIT trANSAKTION <Transaktionsname>
else
ROLLBACK trANSACTION <Transaktionsname | Sicherungspunktname>
create table Sparkonto (
ktnr int primary key,
guthaben money not null default(0)
)
go
create table Girokonto (
ktnr int primary key,
guthaben money not null default(0)
)
go
insert into Sparkonto values(4711, 1000)
insert into Sparkonto values(6969, 2000)
insert into Girokonto values(4711, 1500)
insert into Girokonto (ktnr) values(6969)
go
select * from Sparkonto
select * from Girokonto
begin try
print 'Anz Transaktionen: ' + Cast(@@trancount as varchar(20))
BEGIN trANSACTION ueberweisung
print 'Anz Transaktionen: ' + Cast(@@trancount as varchar(20))
BEGIN trANSACTION innerTrans
print 'Anz Transaktionen: ' + Cast(@@trancount as varchar(20))
Commit transaction
update Sparkonto Set guthaben = guthaben - 1000 where ktnr = 4711
--RAISERROR ('Fehler in einer Transaktion', 15, 1)
update Girokonto Set guthaben = guthaben + 1000 where ktnr = 4711
update Sparkonto Set guthaben = guthaben - 1000 where ktnr = 6969
SAVE trANSACTION spt1
print 'Anz Transaktionen: ' + Cast(@@trancount as varchar(20))
update Girokonto Set guthaben = guthaben + 1000 where ktnr = 6969
RAISERROR ('Fehler in einer Transaktion', 15, 2)
Commit Transaction
end try
begin catch
if Error_state() = 2
begin
ROLLBACK trANSACTION spt1
-- In jedem Fall wird die Transaktion beendet
Commit Transaction
end
else
ROLLBACK trANSACTION
SELECT
ERROR_NUMBER() AS ErrorNumber,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_STATE() AS ErrorState,
ERROR_PROCEDURE() AS ErrorProcedure,
ERROR_LINE() AS ErrorLine,
ERROR_MESSAGE() AS ErrorMessage
end catch
print 'Anz Transaktionen: ' + Cast(@@trancount as varchar(20))
go
select * from Sparkonto
select * from Girokonto
Verbotene Anweisungen in expliziten Transaktionen
Sicherungspunkte
BEGIN trANSACTION <Transaktionsname>
...
SAVE trANSACTION spt1
if <alles ok>
...
if @@error > 0
ROLLBACK trANSACTION spt1 -– Alle Änderungen nach spt1 werden zurückgenommen
COMMIT trANSAKTION <Transaktionsname> -- Alles bis dato nicht zurückgenommenewird bestätigt
else
ROLLBACK trANSACTION <Transaktionsname | Sicherungspunktname>
Autocommit
insert into tab1 values('Anto', 'm')
go begin transaction
insert into tab1 values('Anto', 'm')
commit transaction
go begin transaction
insert into tab1 values('Anto', 'm')
insert into tab1 values('Berta', 'm')
insert into tab1 values('Cäsar', 'm')
commit transaction Impliziter Modus
SET IMPLICIT_trANSACTIONS ON | OFF
SET IMPLICIT_trANSACTIONS ON
insert into tab1 values('Anto', 'm')
// Das Commit ist hier notwendig, da implizit eine Transation eröffnet wurde
// (darf nicht vergessen werden !)
commit transaction
Anzahl der aktiven Transaktionen pro Verbindung
Select @@trANCOUNT
Isolationsstufen
SET TRANSACTION ISOLATION LEVEL {READ COMMITED | READ UNCOMMITED | REPEATEBLE READ | SERIALIZABLE }
Gespeicherte Prozeduren
Anlegen einer gespeicherten Prozedur
create procedure proc_name
[@parametername datentyp [{,@parametername datentyp}]] = [defautlwert][OUTPUT]
AS
{t-sql anweisungen}
Ausgaben
Ein/Ausgabe- Parameter
-- Gibt die id der neu angelegten Zugriffsregel an den Rufer zurück
drop procedure cfg.NewAccessRule
go
create procedure cfg.NewAccessRule
@Entity_id int, -- Entity, für das die Zugriffsregel definiert wird
@role nvarchar(200), -- Rolle, für die der Zugriff definiert wird
@access nchar(2), -- Zugriff: r- lesen, w- schreiben, rw- lesen und schreiben
@id int output -- Ausgabe der id des neuen Datensatzes über Ausgabeparameter
as
-- Resultset- Variable deklarieren
declare @ret table(id int);
INSERT INTO cfg.[EntityAccessRules]
output inserted.id into @ret
VALUES (@role, @Entity_id, @access)
select @id = id from @ret
return -- Durch return wird verhindert, das ein Resultset ausgegeben wird
go
Resultsets zurückgeben
-- Gibt die id der neu angelegten Zugriffsregel an den Rufer zurück
drop procedure cfg.NewAccessRule
go
create procedure cfg.NewAccessRule
@Entity_id int, -- Entity, für das die Zugriffsregel definiert wird
@role nvarchar(200), -- Rolle, für die der Zugriff definiert wird
@access nchar(2) -- Zugriff: r- lesen, w- schreiben, rw- lesen und schreiben
as
-- Resultset- Variable deklarieren
declare @ret table(id int);
INSERT INTO cfg.[EntityAccessRules]
output inserted.id into @ret
VALUES (@role, @Entity_id, @access)
-- Ausgabe des Resultsets
select id from @ret
go
Wert zurückgeben
-- Gibt die id der neu angelegten Zugriffsregel an den Rufer zurück
drop procedure cfg.NewAccessRule
go
create procedure cfg.NewAccessRule
@Entity_id int, -- Entity, für das die Zugriffsregel definiert wird
@role nvarchar(200), -- Rolle, für die der Zugriff definiert wird
@access nchar(2) -- Zugriff: r- lesen, w- schreiben, rw- lesen und schreiben
as
-- Resultset- Variable deklarieren
declare @ret table(id int);
INSERT INTO cfg.[EntityAccessRules]
output inserted.id into @ret
VALUES (@role, @Entity_id, @access)
declare @id int
-- Ausgabe des Resultsets
select @id = id from @ret
return @id
go
Aufruf einer gespeicherten Prozedur
use geoinfo
go
declare @kz char(3)
execute get_lkennung 'Deutschland', @kz output
print @kz
Vorzeitiger Rücksprung aus der Prozedur
return(0)
Benutzerdefinierte Funktionen
Skalarfunktionen
CREATE FUNCTION [dbo].[Erdmasse] ()
RETURNS float
AS
BEGIN
-- Declare the return variable here
DECLARE @EM float
-- Add the T-SQL statements to compute the return value here
SELECT @EM = [Masse_in_kg]
from [dbo].[HimmelskoerperTab]
where [Name] = 'Erde'
-- Return the result of the function
RETURN @EM
END
-- Test
select masse_in_kg / dbo.Erdmasse() as Jupitermasse_in_Erdmassen
from dbo.HimmelskoerperTab
where name = 'Jupiter'
use dmsmin
go
CREATE FUNCTION data.InKB
(
-- Add the parameters for the function here
@valueInByte int
)
RETURNS float
AS
BEGIN
-- Return the result of the function
RETURN @valueInByte / 1024.0
END
GO
-- Test
Select ext, sum(SizeInBytes) as InBytes, data.InKB(sum(SizeInBytes)) as InKB
from data.FileInfos
group by ext
go
Tabellenwertfunktionen
create function dbo.Trabanten_von( @Zentralkoerpername as nvarchar(1000))
returns table
as return (
-- (c) Martin Korneffel, Stuttgart 2015
-- Erzeugt eine View mit denromalisierter Darstellung der Umlaufbahnen
-- Abruf aller Trabanten
select Z.ID as ZentralID, Z.Name as Zentralkoerper, ZY.Name as ZentralkoerperTyp, ZY.ID as ZentralkoerperTypId, Z.Masse_in_kg as Zentralmasse,
T.ID as TrabantID, T.Name as Trabant, TY.Name as TrabantTyp, TY.ID as TrabantTypId, T.Masse_in_kg as Trabantmasse,
U.Umlaufdauer_in_Tagen as Umlaufdauer_Tage
from [dbo].[UmlaufbahnenTab] as U join [dbo].[HimmelskoerperTab] as Z on U.Zentralobjekt_ID = Z.ID
Join [dbo].[HimmelskoerperTab] as T on U.TrabantID = T.ID
Join [dbo].[HimmelskoerperTypenTab] as ZY On Z.HimmelskoerperTyp_ID = ZY.ID
Join [dbo].[HimmelskoerperTypenTab] as TY On T.HimmelskoerperTyp_ID = TY.ID
where Z.Name = @Zentralkoerpername
)
go
-- Test
select Trabant, Trabantmasse / dbo.Erdmasse() as Erdmassen
from dbo.Trabanten_von('Jupiter')
--where TrabantTyp ='Planet'
Trigger
create trigger triggername
on tabellenname | sichtname
[for [after] | instead of] {delete | insert | update}
[with encryption]
as
t-sql anweisungen
Zeitpunkt der Ausführung
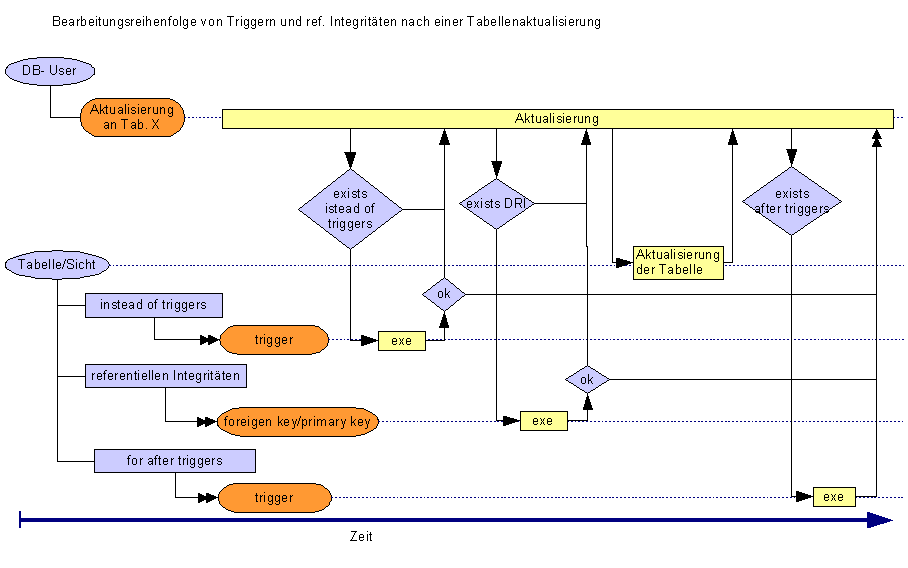
Mehrere
Trigger auf einer Tabelle/Sicht
Spezielle, in Triggern verfügbare Tabellen
Beispiel
create trigger melde_aenderungen
on personal
for delete, insert
as
if exist(select * from inserted)
print 'Sie haben etwas eingefügt'
if exist(select * from deleted)
print 'Sie haben was gelöscht'
go
Regeln beim Implementieren von Triggern
Aufg.
Cursor
use dmsmin
go
-- (c) Martin Korneffel, Stuttgart 2008
-- Rekonstruieren eines Dateipfades aus einer hierarchy_id
if exists(select * from sys.sysobjects where [name] like 'GetPath')
drop procedure data.GetPath
go
Create Procedure data.GetPath
@hierarchy_id as int, --
@path as varchar(1000) output
as
declare @parent_id int
-- Initialisierungen
Select @path = [name], @parent_id = parent_id
from dbo.DirHierarchy
where id = @hierarchy_id
-- Bei der Deklaration eines Cursors wird dieser an eine Ergebnismenge gebunden
Declare cursor_h cursor for
select id, parent_id, [name]
from dbo.DirHierarchy
where id <= @hierarchy_id
order by id desc
-- Vor einem Zugriff muß eine Cursor wie eine Datei geöffnet werden
open cursor_h
-- Solange beim Zugriff über einen Cursor nichts schief läuft, liefert
-- @@fetch_status 0 zurück
declare @akt_name varchar(255)
declare @akt_id int
declare @akt_parent_id int
fetch next from cursor_h
while @@fetch_status = 0 and @parent_id >0
begin
fetch cursor_h into @akt_id, @akt_parent_id, @akt_name
if @akt_id = @parent_id
begin
Set @parent_id = @akt_parent_id
Set @path = @akt_name + '/' + @path
end
end
-- Der Cursor wird geschlossen. Nach erneutem Öffen zeigt er dann wieder auf den
-- ersten Datensatz
close cursor_h
-- Soll ein Cursor nicht weiterverwendet werden, dann ist er freizugeben
deallocate cursor_h
go
-- Test
Declare @path as varchar(1000)
exec data.GetPath 14, @path output
print @path
Informationen über Datenbanken und Tabellen
Version der SQL- Serverinstanz bestimmen
Select @@version
Liste aller aktiven Prozesse auf der Serverinstanz
exec sp_who
Bestimmen der eigenen Prozess- Id
select @@spid
Liste aller Datenbanken auf Serverinstanz
exec sp_databases
go
Liste aller unterstützter Datentypen
exec sp_datatype_info
go
Informationen über ein Datenbankobjekt
exec sp_help name_datenbankobjekt
Indexinfos für eine Tabelle
exec sp_indexes [ @table_server = ] 'table_server'
[ , [ @table_name = ] 'table_name' ]
[ , [ @table_schema = ] 'table_schema' ]
[ , [ @table_catalog = ] 'table_db' ]
[ , [ @index_name = ] 'index_name' ]
[ , [ @is_unique = ] 'is_unique' ]
Liste aller Tabellen in einer Datenbank
use datenbank
go
select * from information_schema.tables
go
Liste aller Spalten von allen Tabellen in einer Datenbank
use datenbank
go
select * from information_schema.columns
go
Liste aller Sichten in einer Datenbank
use datenbank
go
select * from information_schema.views
go